机器学习实现验证码识别
SVM实现
处理步骤
- 获取训练数据图片
- 图片处理
- 模型训练
- 模型测试
获取验证码图片
用的网上已有的验证码图片
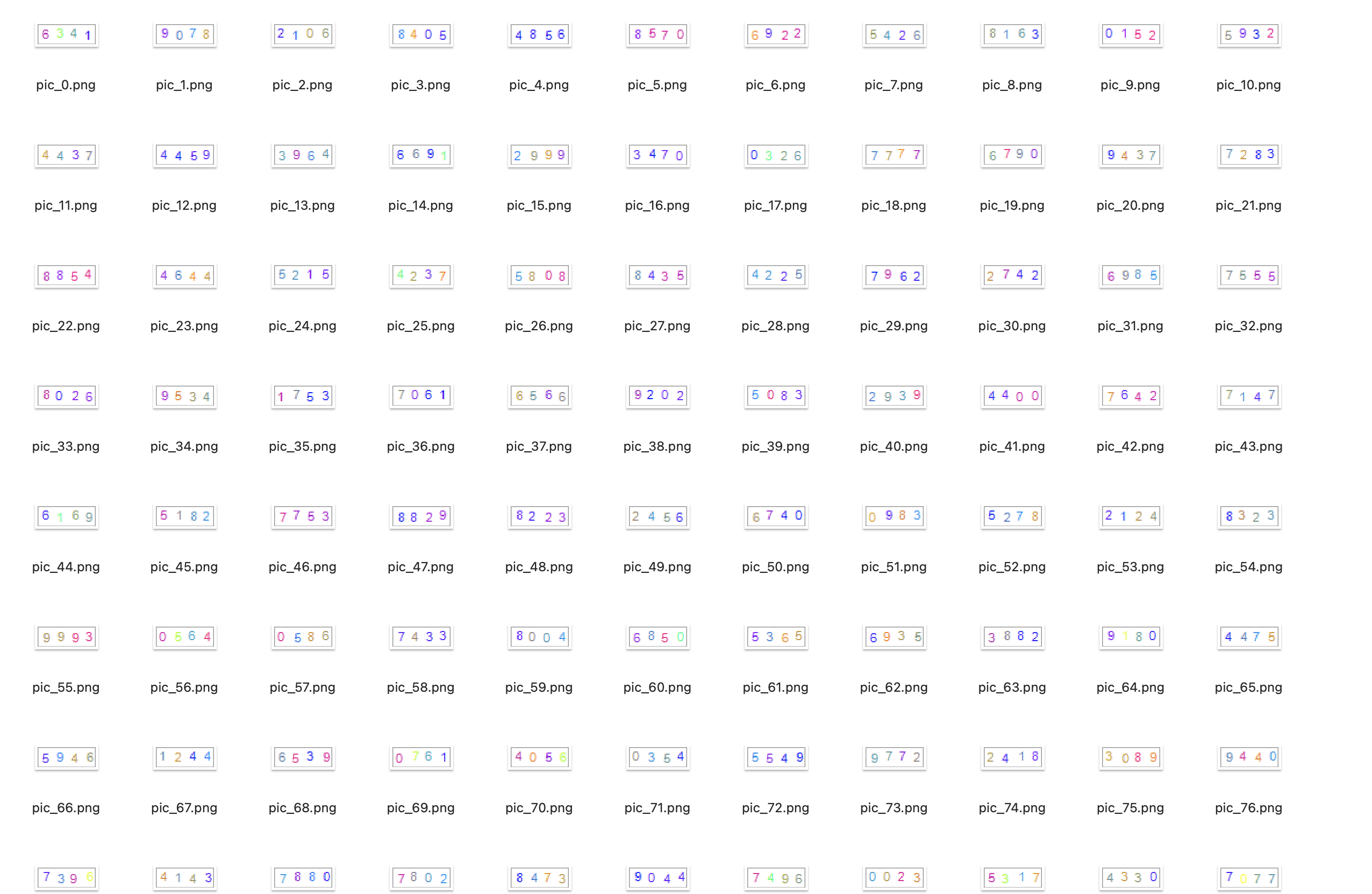
图片处理
图片二值化
- 将RGB彩图转为灰度图
- 将灰度图按照设定阈值转化为二值图
将RGB彩图转为灰度图二值化
#将图片灰度化、二值化
def binarizing(pic):
im = Image.open(root_path+'/'+img_path+'/'+pic)
# 二值化图片 将RGB彩图转为灰度图
im_grey = im.convert('L')
im_binary = im_grey.convert('1')
table = get_bin_table(140)
out = im_grey.point(table, '1')
return out
图片切割
通过观察验证码图片的特征,可以查看

可以得到如下参数:
- 单个字符尺寸是 8*18
- 左右字符和左右边缘相距2个像素
- 字符上下紧挨边缘(即相距0个像素)
则根据此特点利用代码切割字符串
def get_crop_imgs(img):
"""
按照图片的特点,进行切割,这个要根据具体的验证码来进行工作
:param img:
:return:
"""
child_img_list = []
for i in range(4):
x = 2 + i * (8 + 5)
y = 0
child_img = img.crop((x, y, x + 8, y + 18))
child_img_list.append(child_img)
return child_img_list

尺寸归一化
将分割好的字符串按照规定的大小进行存储
for image in images:
o = image.resize((8, 8))
o.save('./tmp1/'+str(n)+'.png','PNG')
n += 1
模型训练
- 给图片打上标签
- 得到图片识别特征
- 模型训练
打标签
利用人工打标签,新建0-9十个文件夹,将肉眼可辨别的一部分分割字符串复制到对应的文件夹中

提取图片特征
读取图片然后遍历每一个像素点提取非白色的像素点,然后加起来,将像素点的和作为图片特征
# 提取SVM用的特征值, 提取字母特征值
def getletter(fn):
img = cv2.imread(fn) # 读取图像
alltz = []
for now_h in range(0, 8):
xtz = []
for now_w in range(0, 18):
b = img[now_h, now_w, 0]
g = img[now_h, now_w, 1]
r = img[now_h, now_w, 2]
btz = 255 - b
gtz = 255 - g
rtz = 255 - r
if btz > 0 or gtz > 0 or rtz > 0:
nowtz = 1
else:
nowtz = 0
xtz.append(nowtz)
alltz += xtz
return alltz
模型训练
使用SVM向量机进行学习训练,生训练结果
# 进行向量机的训练SVM
def trainSVM():
array = extractLetters('tmp')
# 使用向量机SVM进行机器学习
letterSVM = SVC(kernel="linear", C=1).fit(array[0], array[1])
# 生成训练结果
joblib.dump(letterSVM, 'data/letter.pkl')
验证码识别
利用训练的模型,载入模型,然后载入识别的图片,将图片进行灰度化,切割处理,提取特征等操作后,进行识别
def ocrImg(fileName):
clf = joblib.load('data/letter.pkl')
p = Image.open('test_img/%s' % fileName)
#p = cutImg(p)
#b_img = binarizing(p, 170)
b_img=p.convert('L')
#v = vertical(b_img)
imgs=get_crop_imgs(b_img)
#imgs = getSplitImg(b_img, v)
captcha = []
for i, img in enumerate(imgs):
path = 'test_img/letter_%s.png' % i
img.save(path)
data = getletter(path)
data = np.array([data])
# print(data)
oneLetter = clf.predict(data)[0]
# print(oneLetter)
captcha.append(oneLetter)
captcha = [str(i) for i in captcha]
print("the captcha is :%s" % ("".join(captcha)))

参考链接
https://blog.csdn.net/weixin_43790276/article/details/108478270
CNN实现
实验环境
- Win10
- Pytorch
- Python3.8
数据集来源:链接: https://pan.baidu.com/s/1-b8Z1NeH-r2-w30CTOZeug 提取码: 99kw
设计思路
方案选取
验证码形如下图,六位验证码并且存在干扰线,文件名形如1a1c63_d06b8c3fd606c4ca633c523ac408afc7.jpg,文件名前6位为我们标注好了图中的字符串。

起初采取SVM支持向量机进行识别,在干扰线去除效果方面并不好,只能识别一些简单的验证码,因此经过调研之后采取基于CNN卷积神经网络的直接端到端的验证识别技术。
准备工作
one-hot编码
验证码识别也还是分类问题,一共abcdefghijklmnopqrstuvwxyz加上0123456789一共36个类别,因此我们将验证码用one-hot编码代替
captcha_list = list('0123456789abcdefghijklmnopqrstuvwxyz')
captcha_length = 6
验证码文本使用向量表示,采用的是ONE-HOT的形式
# 验证码文本转为向量
def text2vec(text):
vector = torch.zeros((captcha_length, len(captcha_list)))
text_len = len(text)
for i in range(text_len):
vector[i,captcha_list.index(text[i])] = 1
return vector
向量转成验证码文本
# 验证码向量转为文本
def vec2text(vec):
label = torch.nn.functional.softmax(vec, dim =1)
vec = torch.argmax(label, dim=1)
for v in vec:
text_list = [captcha_list[v] for v in vec]
return ''.join(text_list)
如上面的1a1c63向量化结果如下图,1的位置对应着相应的字符
print(text2vec('1a1c63'))
tensor([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.]])
加载数据
使用torch.utils.data.Dataset类,重新实现类的两个魔法方法:len(self),getitem(self)
- len(self): 返回容器元素的个数
- getitem(self) 定义获取容器中指定元素的行为,在获取数据时向量化,统一大小
其中读取图像默认图像为4通道RGBA,A为透明通道,所以需要img.convert('RGB')方便后续训练
# 加载所有图片,并将验证码向量化
def make_dataset(data_path):
img_names = os.listdir(data_path)
samples = []
for img_name in img_names:
img_path = data_path+img_name
target_str = img_name.split('_')[0].lower()
samples.append((img_path, target_str))
return samples
class CaptchaData(Dataset):
def __init__(self, data_path, transform=None):
super(Dataset, self).__init__()
self.transform = transform
self.samples = make_dataset(data_path)
def __len__(self):
return len(self.samples)
def __getitem__(self, index):
img_path, target = self.samples[index]
target = text2vec(target)
target = target.view(1, -1)[0]
img = Image.open(img_path)
img = img.resize((140,44))
img = img.convert('RGB') # img转成向量
if self.transform is not None:
img = self.transform(img)
return img, target
构建神经网络
构建3个卷积层池化层,两个全连接层
定义损失函数用交叉熵
优化器采用Adam
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一层神经网络
# nn.Sequential: 将里面的模块依次加入到神经网络中
self.layer1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1), # 3通道变成16通道,图片:44*140
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2) # 图片:22*70
)
# 第2层神经网络
self.layer2 = nn.Sequential(
nn.Conv2d(16, 64, kernel_size=3), # 16通道变成64通道,图片:20*68
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2) # 图片:10*34
)
# 第3层神经网络
self.layer3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3), # 16通道变成64通道,图片:8*32
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2) # 图片:4*16
)
# 第4层神经网络
self.fc1 = nn.Sequential(
nn.Linear(4*16*128, 1024),
nn.Dropout(0.2), # drop 20% of the neuron
nn.ReLU()
)
# 第5层神经网络
self.fc2 = nn.Linear(1024, 6*36) # 6:验证码的长度, 36: 字母列表的长度
#前向传播
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
return x
训练模型
优先采取GPU进行训练,每2000次做一次输出
def train(epoch_nums):
# 数据准备
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = CaptchaData('I:\\\\Coding\\\\mssb\\\\trains\\\\', transform=transform)
train_data_loader = DataLoader(train_dataset, batch_size=32, num_workers=0, shuffle=True, drop_last=True)
test_data = CaptchaData('I:\\\\Coding\\\\mssb\\\\tests\\\\', transform=transform)
test_data_loader = DataLoader(test_data, batch_size=128, num_workers=0, shuffle=True, drop_last=True)
# 更换设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#device=torch.device("cpu")
print('当前设备是:',device)
net.to(device)
criterion = nn.MultiLabelSoftMarginLoss() # 损失函数
optimizer = torch.optim.Adam(net.parameters(), lr=0.001) # 优化器
# 加载模型
model_path = 'I:\\\\Coding\\\\mssb\\\\model.pth'
if os.path.exists(model_path):
print('开始加载模型')
checkpoint = torch.load(model_path)
net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# 开始训练
i = 1
for epoch in range(epoch_nums):
running_loss = 0.0
net.train() # 神经网络开启训练模式
for data in train_data_loader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) #数据发送到指定设备
#每次迭代都要把梯度置零
optimizer.zero_grad()
# 关键步骤
# 前向传播
outputs = net(inputs)
# 计算误差
loss = criterion(outputs, labels)
# 后向传播
loss.backward()
# 优化参数
optimizer.step()
running_loss += loss.item()
if i % 2000 == 0:
acc = calculat_acc(outputs, labels)
print('第%s次训练正确率: %.3f %%, loss: %.3f' % (i,acc,running_loss/2000))
running_loss = 0
# 保存模型
torch.save({
'model_state_dict':net.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
},model_path)
i += 1
运行
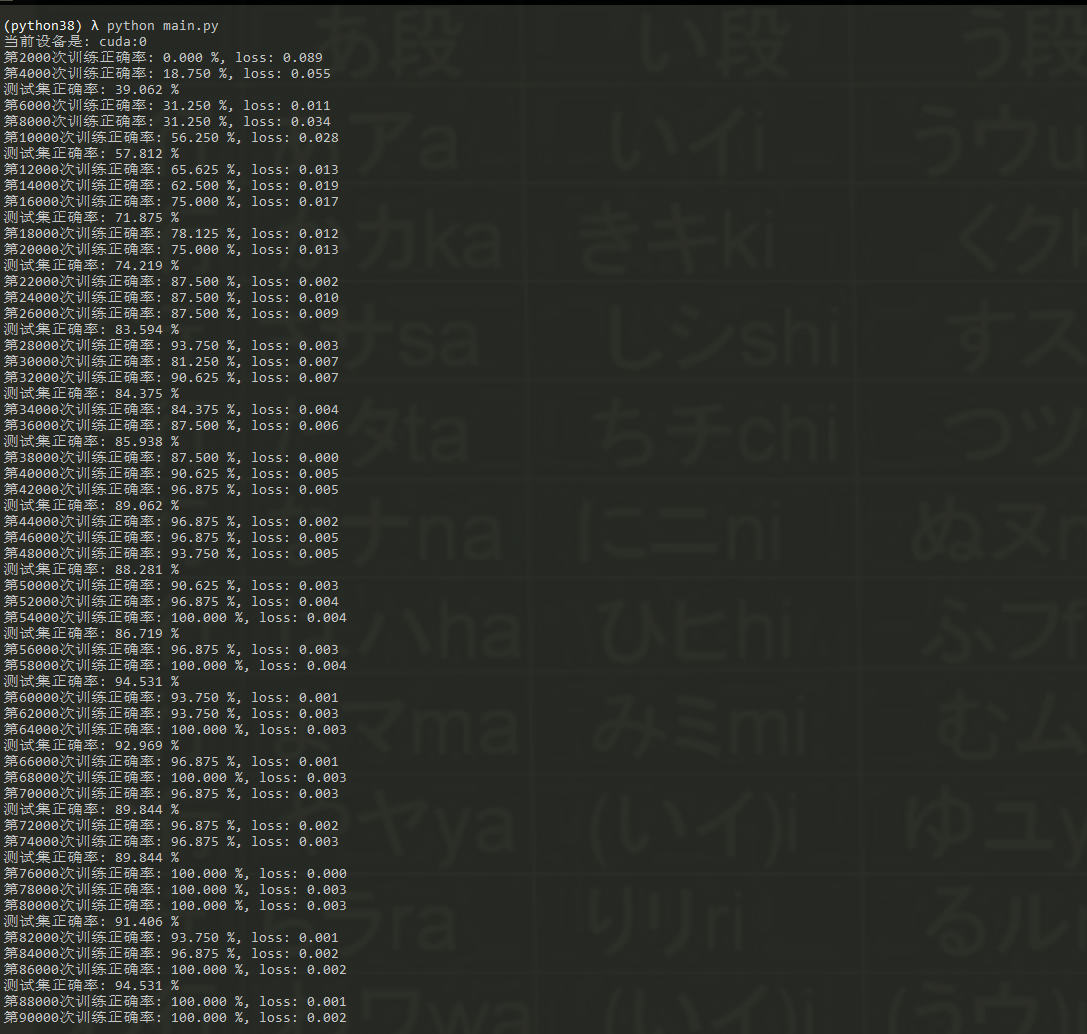
训练截图
(python38) λ python main.py
当前设备是: cuda:0
第2000次训练正确率: 0.000 %, loss: 0.089
第4000次训练正确率: 18.750 %, loss: 0.055
测试集正确率: 39.062 %
第6000次训练正确率: 31.250 %, loss: 0.011
第8000次训练正确率: 31.250 %, loss: 0.034
第10000次训练正确率: 56.250 %, loss: 0.028
测试集正确率: 57.812 %
第12000次训练正确率: 65.625 %, loss: 0.013
第14000次训练正确率: 62.500 %, loss: 0.019
第16000次训练正确率: 75.000 %, loss: 0.017
测试集正确率: 71.875 %
第18000次训练正确率: 78.125 %, loss: 0.012
第20000次训练正确率: 75.000 %, loss: 0.013
测试集正确率: 74.219 %
第22000次训练正确率: 87.500 %, loss: 0.002
第24000次训练正确率: 87.500 %, loss: 0.010
第26000次训练正确率: 87.500 %, loss: 0.009
测试集正确率: 83.594 %
第28000次训练正确率: 93.750 %, loss: 0.003
第30000次训练正确率: 81.250 %, loss: 0.007
第32000次训练正确率: 90.625 %, loss: 0.007
测试集正确率: 84.375 %
第34000次训练正确率: 84.375 %, loss: 0.004
第36000次训练正确率: 87.500 %, loss: 0.006
测试集正确率: 85.938 %
第38000次训练正确率: 87.500 %, loss: 0.000
第40000次训练正确率: 90.625 %, loss: 0.005
第42000次训练正确率: 96.875 %, loss: 0.005
测试集正确率: 89.062 %
第44000次训练正确率: 96.875 %, loss: 0.002
第46000次训练正确率: 96.875 %, loss: 0.005
第48000次训练正确率: 93.750 %, loss: 0.005
测试集正确率: 88.281 %
第50000次训练正确率: 90.625 %, loss: 0.003
第52000次训练正确率: 96.875 %, loss: 0.004
第54000次训练正确率: 100.000 %, loss: 0.004
测试集正确率: 86.719 %
第56000次训练正确率: 96.875 %, loss: 0.003
第58000次训练正确率: 100.000 %, loss: 0.004
测试集正确率: 94.531 %
第60000次训练正确率: 93.750 %, loss: 0.001
第62000次训练正确率: 93.750 %, loss: 0.003
第64000次训练正确率: 100.000 %, loss: 0.003
测试集正确率: 92.969 %
第66000次训练正确率: 96.875 %, loss: 0.001
第68000次训练正确率: 100.000 %, loss: 0.003
第70000次训练正确率: 96.875 %, loss: 0.003
测试集正确率: 89.844 %
第72000次训练正确率: 96.875 %, loss: 0.002
第74000次训练正确率: 96.875 %, loss: 0.003
测试集正确率: 89.844 %
第76000次训练正确率: 100.000 %, loss: 0.000
第78000次训练正确率: 100.000 %, loss: 0.003
第80000次训练正确率: 100.000 %, loss: 0.003
测试集正确率: 91.406 %
第82000次训练正确率: 93.750 %, loss: 0.001
第84000次训练正确率: 96.875 %, loss: 0.002
第86000次训练正确率: 100.000 %, loss: 0.002
测试集正确率: 94.531 %
第88000次训练正确率: 100.000 %, loss: 0.001
第90000次训练正确率: 100.000 %, loss: 0.002
第92000次训练正确率: 96.875 %, loss: 0.002
测试集正确率: 84.375 %
第94000次训练正确率: 96.875 %, loss: 0.002
第96000次训练正确率: 100.000 %, loss: 0.002
测试集正确率: 91.406 %
第98000次训练正确率: 96.875 %, loss: 0.001
第100000次训练正确率: 87.500 %, loss: 0.002
第102000次训练正确率: 96.875 %, loss: 0.002
测试集正确率: 94.531 %
第104000次训练正确率: 100.000 %, loss: 0.001
第106000次训练正确率: 100.000 %, loss: 0.002
第108000次训练正确率: 96.875 %, loss: 0.002
测试集正确率: 88.281 %
最后选取了5000个样本进行测试,测试结果如下
验证码是:3p6hys, 预测为:3p6hys,结果正确
验证码是:3p6k32, 预测为:3p6k32,结果正确
验证码是:3p6m66, 预测为:3p6m66,结果正确
验证码是:3p6p2f, 预测为:3p6p2f,结果正确
验证码是:3p6p2r, 预测为:3p6p2r,结果正确
验证码是:3p6p37, 预测为:3p6p37,结果正确
验证码是:3p6p54, 预测为:3p6p54,结果正确
验证码是:3p6p58, 预测为:3p6p58,结果正确
验证码是:3p6p76, 预测为:3p6p76,结果正确
验证码是:3p6p8j, 预测为:3p6p8j,结果正确
验证码是:3p6pdc, 预测为:3p6pdc,结果正确
验证码是:3p6r2c, 预测为:3p6r2c,结果正确
验证码是:3p6r2y, 预测为:3p6r2y,结果正确
验证码是:3p6r4y, 预测为:3p6r4y,结果正确
验证码是:3p6t8a, 预测为:3p6t8a,结果正确
验证码是:3p6ve5, 预测为:3p6ve5,结果正确
验证码是:3p6vt2, 预测为:3p6vt2,结果正确
验证码是:3p6y34, 预测为:3p6y34,结果正确
验证码是:3p6ymr, 预测为:3p6ymr,结果正确
验证码是:3p7ap3, 预测为:3p7ap3,结果正确
验证码是:3p7bs4, 预测为:3p7bs4,结果正确
验证码是:3p7bsx, 预测为:3p7bsx,结果正确
...
...
验证码是:3p8c7e, 预测为:3p8c7e,结果正确
验证码是:3p8dh7, 预测为:3p8dh7,结果正确
验证码是:3p8ff1, 预测为:3p8ff1,结果正确
验证码是:3p8fs2, 预测为:3p8fs2,结果正确
验证码是:3p8htx, 预测为:3p8htx,结果正确
验证码是:3p8v44, 预测为:3p8v44,结果正确
验证码是:3p8xf5, 预测为:3p8xf5,结果正确
验证码是:3p8y83, 预测为:3p8y83,结果正确
验证码是:3p8y8k, 预测为:3p8y8k,结果正确
最终正确率:0.9789285714285714
最后利用argsparse模块方便终端调用识别,最后运行结果
parser = argparse.ArgumentParser(description='valite the captcha.')
parser.add_argument('-d', dest='dir',help='input the dir you need to valite')
args = parser.parse_args()
if args.dir is not None:
model_path = 'I:\\\\Coding\\\\mssb\\\\model.pth'
if os.path.exists(model_path):
print('开始加载模型')
checkpoint = torch.load(model_path)
net.load_state_dict(checkpoint['model_state_dict'])
transform = transforms.Compose([transforms.ToTensor()])
vil_data = CaptchaData(args.dir, transform=transform)
vil_data_loader = DataLoader(vil_data, batch_size=1, num_workers=0, shuffle=False)
#开始预测
acc = 0
for img, target in vil_data_loader:
pre = predict(img)
print(f'预测结果{pre}')
